We address language-conditioned robotic manipulation using flow-based trajectory generation, which enables training on human and web videos of object manipulation
and requires only minimal embodiment-specific data. This task is challenging, as object trajectory generation from premanipulation images and natural language instructions requires appropriate instruction-flow alignment.
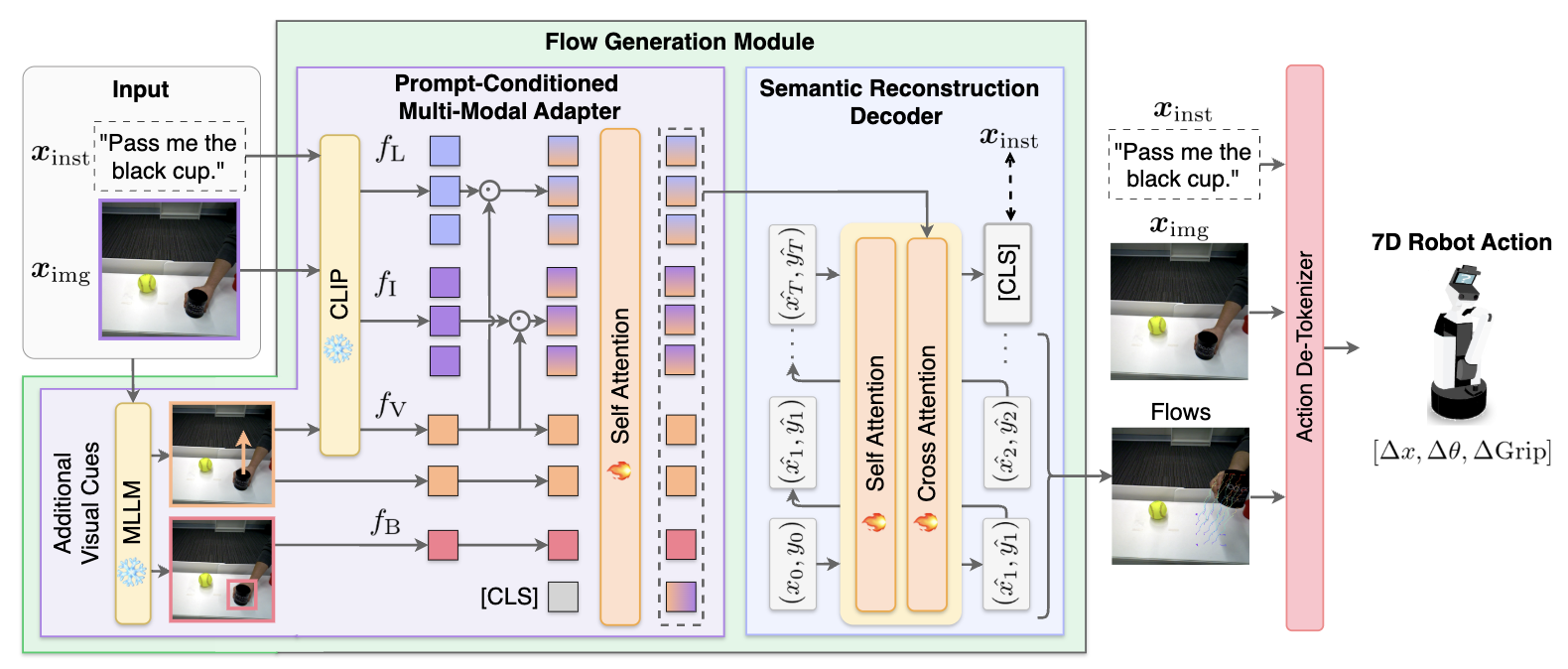
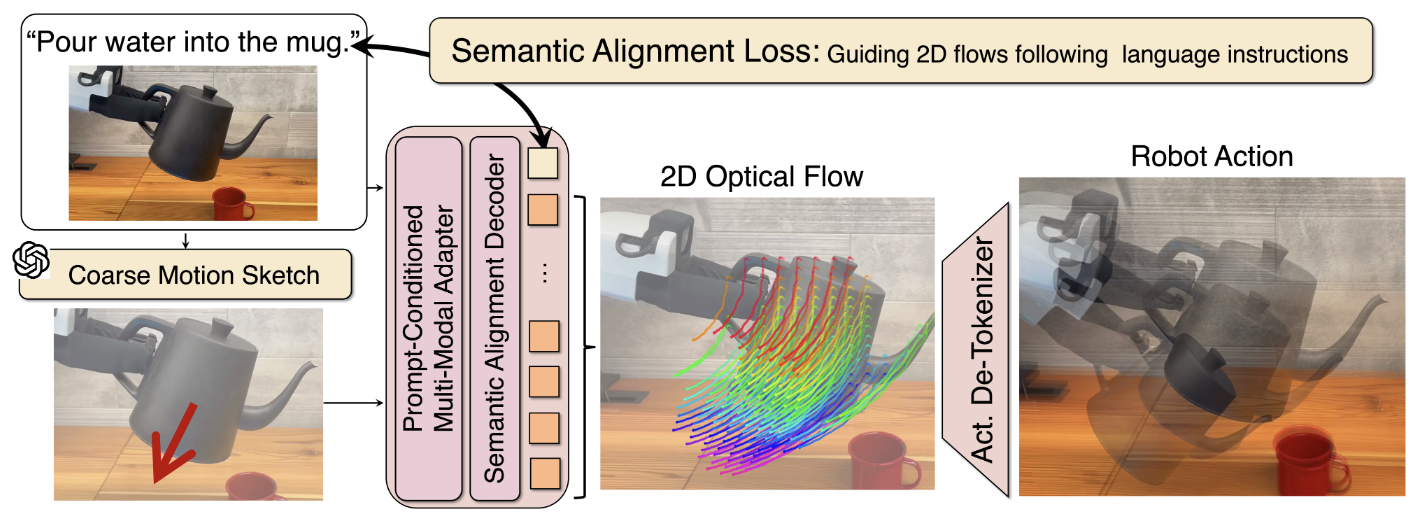
To tackle this challenge, we propose the flow-based Language Instructionguided open-Loop ACtion generator (LILAC). This flow-based Vision-Language-Action model (VLA) generates object-centric 2D optical flow from an RGB image and a natural language instruction, and converts the flow into a 6-DoF manipulator trajectory. LILAC incorporates two key components: Semantic Alignment Loss, which strengthens language conditioning to generate instruction-aligned optical flow, and PromptConditioned Cross-Modal Adapter, which aligns learned visual prompts with image and text features to provide rich cues for flow generation.
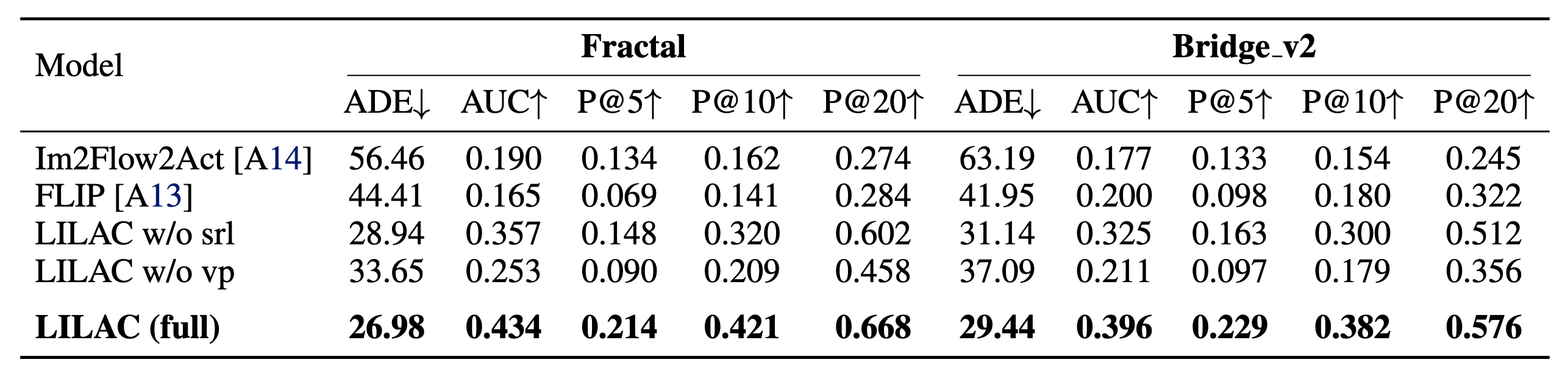
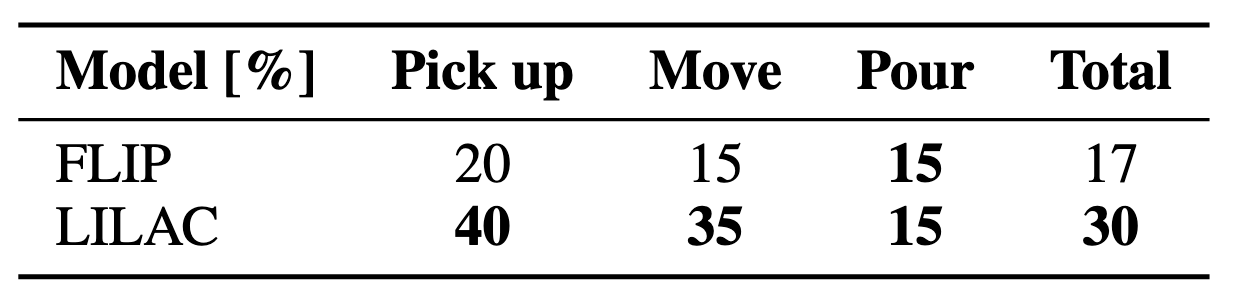
Experimentally, our method outperformed existing approaches in generated flow quality across multiple benchmarks. Furthermore, in physical object manipulation experiments using free-form instructions, LILAC demonstrated a superior task success rate compared to existing methods.